 At Mental Canvas, Dave Burke and I recently resolved a memory leak bug in our iOS app using the Metal graphics libraries. Memory management on Metal has had a few good WWDC talks but has surprisingly little chatter on the web, so I thought I’d share our process and findings.
At Mental Canvas, Dave Burke and I recently resolved a memory leak bug in our iOS app using the Metal graphics libraries. Memory management on Metal has had a few good WWDC talks but has surprisingly little chatter on the web, so I thought I’d share our process and findings.
- The issue: a transient memory spike
- iOS / iPadOS memory limits
- Forming hypotheses
- Tools at hand
- Findings
- Conclusion
- References
The issue: a transient memory spike
Our sketching app does a lot of rendering to intermediate, offscreen textures. In the process, we generate (and quickly discard) a lot of intermediate textures. A lot of that rendering happens in a continuous batch on a dedicated thread, without yielding execution back to the operating system.
A consequence of that behavior: our memory footprint grows rapidly until we hit the critical threshold — on a 3 GB iPad Air, about 1.8 GB — and then iOS summarily kills the app. From our app’s perspective, memory footprint is only growing gradually, as most of the memory usage is temporary intermediate rendertargets; they should be freed and available for reuse. But from the operating system’s perspective, it considers all of those temporaries to still be in use.
Which led us to the question: why? And how do we figure out which temporaries are leaking, and which Metal flag / call will allow us to return that data to the operating system?
iOS / iPadOS memory limits
From our empirical reviews of the various tools, we can say the following:
- The XCode Memory Gauge precisely reflects what the operating system thinks your app’s size is (as advertised in many WWDC talks).
- The great new
os_proc_available_memory()call in iOS13 appears to precisely match the XCode Memory Gauge. A delta betweenos_proc_available_memory()at app startup and later in the app represents memory consumption in the same manner that the OS sees it. - The operating system seems to kill an app once its usage hits roughly system memory minus 1GB
- Test systems: a 3GB iPad Air (2019) and a 4GB iPad Pro (2018), running both iOS12 and iOS13
- API reported RAM: 2.8GB and 3.6GB respectively
- Crashes at 1.8GB and 2.7GB memory usage
- Be cautious of other memory metrics: neither XCode’s GPU Frame Capture memory view, the Metal System Trace Instrument nor the Memory Graph Instrument appear to give totals that line up cleanly with the XCode Memory Gauge.
- Ultimately, I got GPU Frame Capture to give me great data — but with an awareness of when its snapshot is taken, which is typically at the end of rendering a visible frame, and after some operating system activity has happened.
Forming hypotheses
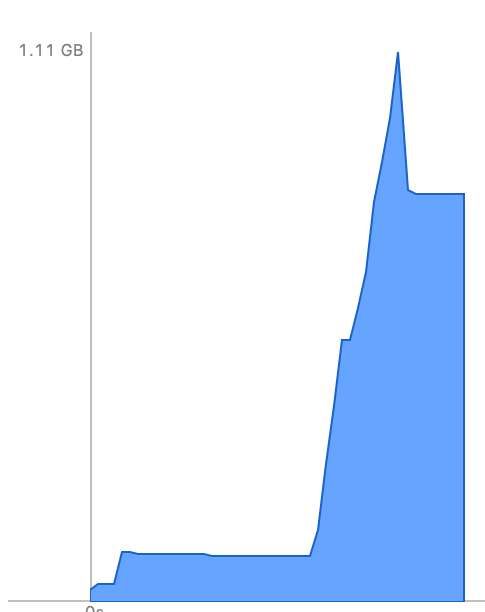
One thing that caught my eye immediately: when working with a smaller batch of data (which didn’t hit the memory limit), the XCode memory graph showed an “overshoot.” During processing in the graph here, we hit a peak of 1.1GB memory used, but then subsided back down to a steady state of about 840MB once processing completed.

This suggested that there was not a true memory leak — clearly our code only referenced 840MB of memory, and once the operating system / GPU / drivers had time to “clean up” any unreferenced memory, 260MB was being released. If we could avoid that spike, our peak memory usage would be 25% lower.
So, why would that happen? Where are those large blocks of data being held?
The large data objects are virtually all MTLTexture objects. They’re being written (i.e., used as rendertargets) in one phase of our processing, then being read (rendered to another rendertarget) in a later phase. Mechanically in Metal, that means a reference is being held by one or more MTLCommandBuffers that hasn’t completed executing yet.
As pseudocode on the CPU side, that looks like this:
1 start visible frame
2 for each item in batch {
3 allocate MTLCommandBuffer
4 allocate temporary MTLTexture
5 add "Write to temporary MTLTexture" commands to MTLCommandBuffer
6 add "Read from temporary MTLTexture" command to MTLCommandBuffer
7 send list of commands to GPU ("commit")
// Optional. This throttles throughput in favour of reducing memory
// footprint.
8 CPU wait until GPU completes execution of MTLCommandBuffer
9 }
10 render batch results to visible frame
11 present visible frame to user
Those MTLTexture objects are therefore held in several places, via reference counting. This allows us to formulate several hypotheses:
- CPU-side reference counting of MTLTexture in line 4. When a loop iteration completes in line 9, the last CPU pointer to the MTLTexture (and MTLCommandBuffer) goes out of scope, and the CPU will not hold any active references. However, Objective C / Swift may not free the MTLTexture memory immediately, as it relies on autorelease pools for reference-counted objects.
- Reference to MTLTexture held by MTLCommandBuffer. Even if there are no CPU-side MTLTexture references outstanding, there’s obviously still several references to the MTLTexture held by the command buffer. (i.e., “Write to here… now, read from here”.) Presumably, once the GPU executes all commands referencing a given MTLTexture, it will release the references to those MTLTextures. But — what is the timing of that release? How does it interact with autorelease pools, given that there’s potential for GPU/CPU contention?
- Requirement to use MTLPurgeable flags. There are various Metal MTLPurgeable flags that can be set on a texture/buffer that might be required for more immediate reuse of a buffer. Metal is currently a little thin on documentation, and it’s hard to tell what’s required.
- Incorrect GPU parallelism. In theory, the GPU will execute the “write to temporary” commands (line 4) before “read from temporary” (line 5). But what if the parallelism there isn’t specified correctly, and the reading task happens in parallel with the writing, and maybe even completes before writing has completed? Then, the wait in line 8 will still leave “writing” tasks executing, and their temporary memory still in use. Multiple loop iterations might execute in parallel, with higher memory usage.
- Requirement for more advanced Metal data structures. Metal does offer the MTLHeap data structure for more manual control over memory management. This structure has an explicit setAliasable call to reuse a texture/buffer’s memory (i.e., free it). It’s possible that the behaviour we want is only possible via an MTLHeap.
Tools at hand
- The Metal System Trace instrument gives a good history of app execution across both CPU and GPU and was helpful for confirming that GPU parallelism was correct. While it shows the timing of mid-frame memory allocations, it doesn’t tell us anything useful about memory release timing.
- The Memory Graph instrument wasn’t useful. It’s not really helpful for GPU-side information, and it didn’t give any clear way to understand autorelease pool behaviour on the CPU side.
- XCode’s GPU Frame Capture feature provides a great snapshot of memory usage, including a browseable list of all allocated textures, their sizes and their flags. It’s designed to work on a single visible frame of animation, and the snapshot of memory that it normally displays is taken after line 11 of my pseudocode — i.e., the “steady state” memory usage, but not the intermediate “peak” mid-loop. However, if you use the manual MTLCaptureScope class, you can control the timing of the memory snapshot, and get a view of the peak memory usage. As an alternative, you can actually use breakpoints to control GPU frame capture.

Findings
Of the five hypotheses I presented, it turned out that #1 was the key. We had CPU-side references that lasted longer than we wanted — because of the way that autorelease pools operate.
Let’s talk through each hypothesis:
- CPU-side references: at the end of each loop iteration, we indeed had no CPU-side or GPU-side references remaining. But — the CPU-side references do not get freed until the end of an autorelease pool block is reached. That didn’t happen until we returned control to the operating system, after presenting our visible frame.
We found this using a GPU Frame Capture memory snapshot at the end of a loop iteration. In that snapshot, MTLTextures were still showing up in the list of allocated objects. We added an @autoreleasepool block around each loop iteration, and took a new memory snapshot after the autorelease pool drained — and lo and behold, the memory was now freed promptly. - References held by MTLCommandBuffers: it appears that MTLCommandBuffers are quite smart about tracking their data dependencies. We didn’t confirm whether textures references are released as commands execute, but clearly references are fully released when the MTLCommandBuffer completes.
- Documentation on topics such as MTLHazardTrackingMode suggests that you can turn off the data dependency tracking, implying that intelligent dependency tracking is the default.
- GPU flags like MTLPurgeableState: at WWDC, we got a tip from an Apple engineer to use an MTLCommandBuffer completionHandler and use that to set the purgeable state on the MTLTextures to make them freeable. That might be helpful with an MTLHeap, but was unnecessary for us — with CPU side references released via @autoreleasepool, the purgeable state didn’t need to be set.
- Incorrect GPU parallelism: using MTLCommandBuffer and regular MTLTextures, this was not an issue; it understood our data dependencies pretty well and ensured sensible parallelism. This was confirmed with the Metal System Trace instrument. When we tried using MTLHeap — with more manual memory management — it was certainly possible to get incorrect GPU parallelism.

- Advanced data structures (MTLHeap): we explored this more manual memory management system extensively, but it didn’t prove necessary for our situation, and didn’t address the underlying CPU-side autorelease pool issue.
Conclusion
With a newfound respect for autorelease pools, we’d solved the issue. The revised pseudocode is shown below, including debugging capture after processing item #10. New lines are in bold.
1 start visible frame
2 start GPU Frame Capture
3 for each item in batch {
4 @autoreleasepool {
5 allocate MTLCommandBuffer
6 allocate temporary MTLTexture
7 add "Write to temporary MTLTexture" commands to MTLCommandBuffer
8 add "Read from temporary MTLTexture" command to MTLCommandBuffer
9 send list of commands to GPU ("commit")
10 CPU wait until GPU completes execution of MTLCommandBuffer
11 print "Before drain: " + os_proc_memory_available()
12 }
13 print "After drain: " + os_proc_memory_available()
14 if (index == 10)
15 end GPU Frame Capture
16 }
10 render batch results to visible frame
11 present visible frame to user
And indeed, the transient memory spike was gone. The memory available after draining the autoreleasepool appeared to match the size of the temporary buffers allocated. We had a nice smooth rise to the steady state, and a 25% reduction in peak memory usage. We still had to work some magic to operate on big content — 1.7GB will still only get you so far — but predictable transient memory behaviour was a big step forward.

References
- Reducing the Memory Footprint of Metal Apps
- Developing Optimized Metal Apps and Games video Part 3: Memory Footprint. (Do use the searchable, hyperlinked transcript!)
- Image Filter Graph with heaps and fences sample code
- Archived documentation on MTLHeap and fences adds useful supplemental detail beyond the current documentation.